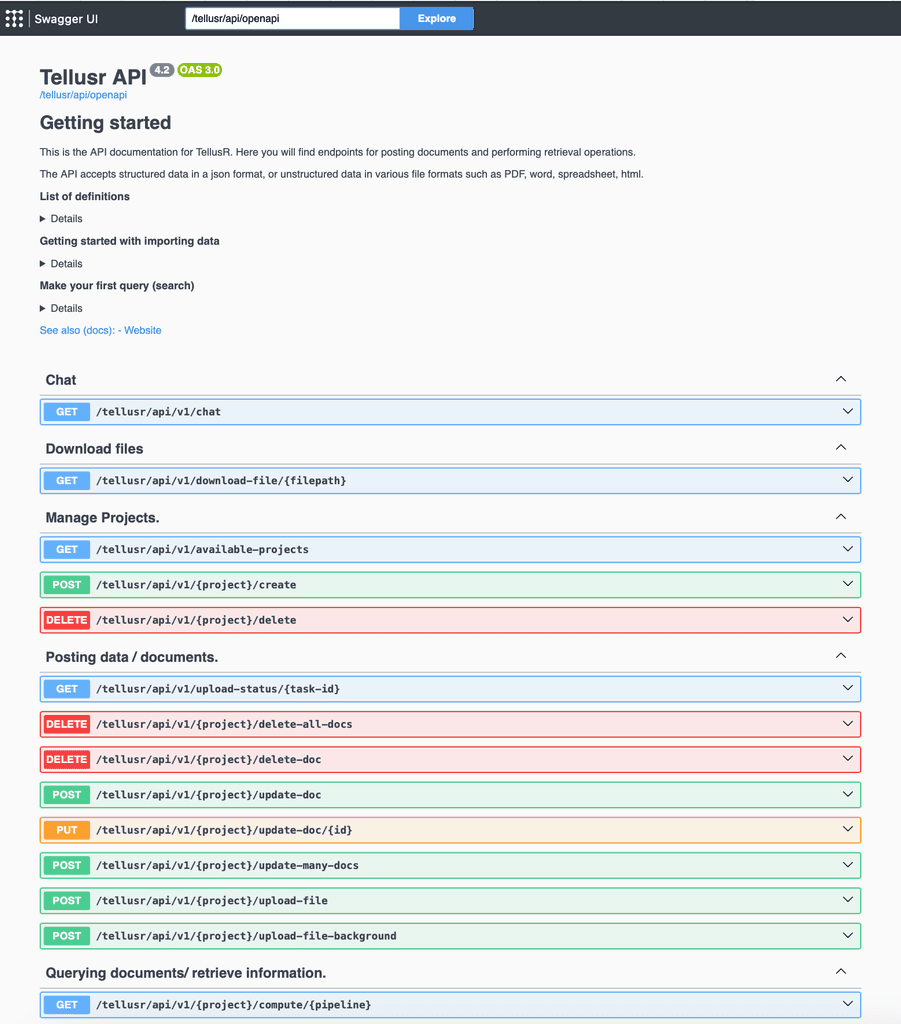

Plattform og arkitektur
- Headless og API-first arkitektur – all funksjonalitet kan integreres direkte i egne applikasjoner.
- Høy konfigurerbarhet med full kontroll via dokumenterte API-endepunkter og konfigurasjonsgrensesnitt.
- GPU-støtte og skalerbar kjøring på tvers av flere servere.
- Fleksibel drift: kjør lokalt, på egen server eller i valgfri sky – uten vendor lock-in.

















